0 Likes
Financial Data Mining based on Support Vector Machines and Ensemble Learning
Last updated on April 6, 2021, 3:13 p.m. by mayank
In the paper titled ‘Financial Data Mining based on Support Vector Machines and Ensemble Learning’, the authors Shi Lei, Ma Xinming, Xi Lei, Hu Xiaohong have classified the financial data using support vector machines and the ensemble learning methods. The datasets used are the German credit dataset and the Credit approval dataset. The authors have given an overview of the SVMs and Adaboost used for ensemble learning followed by the results of their experimentations.
SVMs (Support Vector Machines):
SVMs are based on minimizing the risk, and find an optimal hyperplane for the given classes. For binary classification, the ‘y’ values are considered as {+1,-1}. The hyperplane equation is given by w*x+b=0, where ‘w’ is the vector normal to the hyperplane and b is the offset. The constraint relationship derived with respect to the hyperplane is yi(w*xi+b) >=1. We try to maximize the distance between support vectors i.e. 2/|w|, i.e. minimize 0.5*|w|2. This is achieved with the help of Lagrange’s multipliers, giving us the following equation-
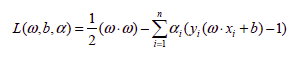
Subject to the two linear constraints-
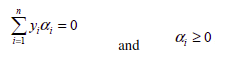
This is further solved by the quadratic programming. For non-linear boundaries, kernels are be used.
Ensemble Learning
Boosting is used in Ensemble learning approach. Adaboost, used here, basically changes the weights of the training data-points after each instance based on the misclassification by the algorithm. In short, Adaboost calculates the weighted training error, sets alpha and updates the weights. A brief of the algorithm is given below.
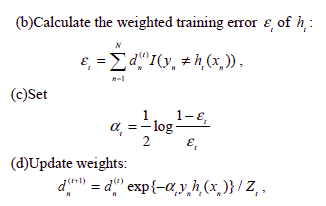
Experimentation and Results:
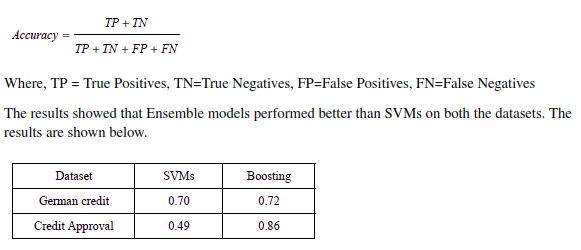
The accuracy is calculated as
Important Sentences
- Support vector machines (SVMs) [1], introduced by Vapnik, are a kind of structural risk minimization based learning algorithms and have better generalization abilities comparing to other traditional empirical risk minimization based learning algorithms.
- The purpose of ensemble learning is to build a learning model to integrate a number of base learning models for obtaining better generalization performance [2].
- The experimental results indicate that compared with SVMs, ensemble learning achieves obvious improvement of performance.
- Then partition hyperplane can be defined as w.x+b=0, where is the normal vector of the partition hyperplane, and b is the offset of hyperplane. For making the partition hyperplane as far from the point in training dataset as possible, a partition hyperplane to make the bilateral blank area, i.e., 2/|w|2
maximum must be found.
- For making the learning algorithm to minimize the expected error over different input distributions, it changes the weights of the training instances after each trial based on the base classifier’s misclassifications [4]. It explicitly alters the distribution of training data fed to every individual classifier, specifically weights of each training sample.
- Two dataset from the UCI machine learning dataset repository, i.e., the German credit dataset and Credit Approval dataset [5], are used in experiment.
- On German credit dataset, the prediction Accuracy of boosting is 72%, which beats SVMs by about 2%. On Credit Approval dataset, The prediction Accuracy of boosting is 86%, which is approximately 37% higher than that of SVMs.
0 Likes

by mayank
KJ Somaiya College of Engineering Mumbai

Suggested Posts



