2 Likes
Data Analysis SPPU all MCQ's for online exam
Last updated on March 16, 2021, 7:47 a.m. by Akshay Sadawarte

DA Objective Questions
(MCQ /True or False / Fill up with Choices )
Here are all MCQs of DA(Data Analysis) of SPPU 4th year/final year with answers for online examination SPPU.
1. Which of the following is not an example of Social Media?
a. Twitter
b. Google
c. Insta
d. Youtube
2. By 2025, the volume of digital data will increase to
a. TB
b. YB
c. ZB d. EB
3. For Drawing insights for Business what are needed?
a. Collecting the data
b. Storing the data
c. Analysing the data
d. All the above
4. Does Facebook uses "Big Data " to perform the concept of Flashback? Is this True or False.
a. TRUE
b. FALSE
5. The Process of describing the data that is huge and complex to store and process is known as
a. Analytics
b. Data mining
c. Big Data
d. Data Warehouse
6. Data generated from online transactions is one of the example for volume of big data. Is this true or False.
a. TRUE
b. FALSE
7. Velocity is the speed at which the data is processed
a. TRUE
b. FALSE
8. __________ have a structure but cannot be stored in a database.
a. Structured
b. Semi-Structured
c. Unstructured
d. None of these
9. ___________ refers to the ability to turn your data useful for business.
a. Velocity
b. Variety
c. Value
d. Volume
10. Value tells the trustworthiness of data in terms of quality and accuracy.
a. TRUE
b. FALSE
11. GFS consists of a _________ Master and ____________ Chunk Servers
a. Single, Single
b. Multiple, Single
c. Single, Multiple
d. Multiple, Multiple
12. Files are divided into __________ sized Chunks.
a. Static
b. Dynamic
c. Fixed
d. Variable
13. ______________ is an open source framework for storing data and running application on clusters of commodity hardware.
a. HDFS
b. Hadoop
c. MapReduce
d. Cloud
14. HDFS Stores how much data in each clusters that can be scaled at any time?
a. 32
b. 64
c. 128
d. 256
15. Hadoop MapReduce allows you to perform distributed parallel processing on large volumes of data quickly and efficiently… is this MapReduce or Hadoop… i.e statement is True or False
a. TRUE
b. FALSE
16. Hortonworks was introduced by Cloudera and owned by Yahoo.
a. TRUE
b. FALSE
17. Hadoop YARN is used for Cluster Resource Management in Hadoop Ecosystem.
a. TRUE
b. FALSE
18. Google Introduced MapReduce Programming model in 2004.
a. TRUE
b. FALSE
19. ____________ phase sorts the data & ___________ creates logical clusters.
a. Reduce, YARN
b. MAP, YARN
c. REDUCE, MAP
d. MAP, REDUCE
20. There is only one operation between Mapping and Reducing is it True or False…
a. TRUE
b. FALSE
21. _________ is factors considered before Adopting Big Data Technology.
a. Validation
b. Verification
c. Data
d. Design
22. ________ for improving supply chain management to optimize stock management, replenishment, and forecasting;
a. Descriptive
b. Diagnostic
c. Predictive
d. Prescriptive
23. which among the following is not a Data mining and analytical applications?
a. profile matching
b. social network analysis
c. facial recognition
d. Filtering
24. _________ as a result of data accessibility, data latency, data availability, or limits on bandwidth in relation to the size of inputs.
a. Computation-restricted throttling
b. Large data volumes
c. Data throttling
d. Benefits from data parallelization
25. As an example, an expectation of using a recommendation engine would be to increase same-customer sales by adding more items into the market basket.
a. Lowering costs
b. Increasing revenues
c. Increasing productivity
d. Reducing risk
26. Which storage subsystem can support massive data volumes of increasing size.
a. Extensibility
b. Fault tolerance
c. Scalability
d. High-speed I/O capacity
27. ________ provides performance through distribution of data and fault tolerance through replication
a. HDFS
b. PIG
c. HIVE
d. HADOOP
28. __________ is a programming model for writing applications that can process Big Data in parallel on multiple nodes.
a. HDFS
b. MAP REDUCE
c. HADOOP
d. HIVE
29. ______________ takes the grouped key-value paired data as input and runs a Reducer function on each one of them.
a. MAPPER
b. REDUCER
c. COMBINER
d. PARTITIONER
30. ______________ is a type of local Reducer that groups similar data from the map phase into identifiable sets.
a. MAPPER
b. REDUCER
c. COMBINER
d. PARTITIONER
31. While Installing Hadoop how many xml files are edited and list them?
i. core-site.xml
ii. hdfs-site.xml
iii. mapred.xml
iv. yarn.xml
32. Write the code for core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>D:\hadoop\temp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:50071</value>
</property>
</configuration>
</?xml >
33. Write the code for hdfs-site.xml?
(will update soon!)
34. Movie Recommendation systems are an example of
1. Classification 2. Clustering 3. Reinforcement Learning 4. Regression
a. 2 Only
b. 1 and 2
c. 1 and 3
d. 2 and 3
35. Sentiment Analysis is an example of
1. Regression 2. Classification 3. Clustering 4 Reinforcement Learning
a. 1, 2 and 4
b. 1 and 3
c. 1, 2 and 3
d. 1 and 2
36. Can decision trees be used for performing clustering?
a. True
b. False
37. What is the minimum no. of variables/ features required to perform clustering?
1. 0
2. 1
3. 2
4. 3
38. For two runs of K-Mean clustering is it expected to get same clustering results?
1. Yes 2. No
39. Which of the following can act as possible termination conditions in K-Means?
1. For a fixed number of iterations.
2. Assignment of observations to clusters does not change between iterations. Except for cases with a bad local minimum.
3. Centroids do not change between successive iterations. 4.Terminate when RSS falls below a threshold.
a. 1, 3 and 4
b. 1, 2 and 3
c. 1, 2 and 4
d. All of the above
40. Which of the following algorithm is most sensitive to outliers?
1. K-means clustering algorithm
2. K-medians clustering algorithm
3. K-modes clustering algorithm
4. K-medoids clustering algorithm
41. In the figure below, if you draw a horizontal line on y- axis for y=2. What will be the number of clusters formed?
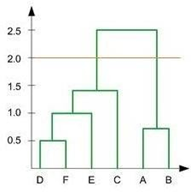
1. 1
2. 2
3. 3
4. 4
42. In which of the following cases will K-Means clustering fail to give good results?
1. Data points with outliers
2. Data points with different densities
3. Data points with round shapes
4. Data points with non-convex shapes
a. 1 and 2
b. 2 and 3
c. 2 and 4
d. 1, 2 and 4
43. The discrete variables and continuous variables are two types of
a. Open end classification
b. Time series classification
c. Qualitative classification
d. Quantitative classification
44. Bayesian classifiers is
1. A class of learning algorithm that tries to find an optimum classification of a set of examples using the probabilistic theory.
2. Any mechanism employed by a learning system to constrain the search space of a hypothesis
3. An approach to the design of learning algorithms that is inspired by the fact that when people encounter new situations, they often explain them by reference to familiar experiences, adapting the explanations to fit the new situation.
4. None of these
45. Classification accuracy is
1. A subdivision of a set of examples into a number of classes
2. Measure of the accuracy, of the classification of a concept that is given by a certain theory
3. The task of assigning a classification to a set of examples
4. None of these
46. Euclidean distance measure is
1. A stage of the KDD process in which new data is added to the existing selection.
2. The process of finding a solution for a problem simply by enumerating all possible solutions according to some pre-defined order and then testing them
3. The distance between two points as calculated using the Pythagoras theorem
4. None of these
47. ------------------- is good at handle missing data and support both the kind of attributes ( i.e Categorial and Continuous attributes )
a. ID3.
b. C4.5.
c. CART.
d. Naïve Bayes.
48. Decision trees use ____________, in that they always choose the option that seems the best available at that moment.
a. Greedy Algorithms.
b. Divide and Conquer.
c. Backtracking.
d. Shortest Path Method.
49. Decision trees cannot handle categorical attributes with many distinct values, such as country codes for telephone numbers.
a. TRUE
b. FALSE
50. ________________ are easy to implement and can execute efficiently even without
prior knowledge of the data, they are among the most popular algorithms for classifying text documents.
a. ID3
b. Naïve Bayes classifiers
c. CART
d. None of these.
51. High entropy means that the partitions in classification are
a. Pure
b. Not pure
c. Useful
d. Useless
52. Which of the following statements about Naive Bayes is incorrect?
a. Attributes are equally important.
b. Attributes are statistically dependent of one another given the class value.
c. Attributes are statistically independent of one another given the class value.
d. Attributes can be nominal or numeric
53. John flies frequently and likes to upgrade his seat to first class. He has determined that if he checks in for his flight at least two hours early, the probability that he will get an upgrade is 0.75; otherwise, the probability that he will get an upgrade is 0.35. With his busy schedule, he checks in at least two hours before his flight only 40% of the time. Suppose John did not receive an upgrade on his most recent attempt. What is the probability that he did not arrive two hours early?
a. 0.892
b. 0.796
c. 0.685
d. 0.999
54. Point out the wrong statement.
a. k-nearest neighbor is same as k-means
b. k-means clustering is a method of vector quantization
c. k-means clustering aims to partition n observations into k clusters
d. none of the mentioned
55. Consider the following example “How we can divide set of articles such that those articles have the same theme (we do not know the theme of the articles ahead of time) " is this:
1. Clustering
2. Classification
3. Regression
4. None of These
56. Can we use K Mean Clustering to identify the objects in video?
1. Yes 2. No
57. Clustering techniques are ______________ in the sense that the data scientist does not determine, in advance, the labels to apply to the clusters.
1. Unsupervised
2. Supervised
3. Reinforcement
4. Neural network
58. After performing K-Means Clustering analysis on a dataset, you observed the following
dendrogram. Which of the following conclusion can be drawn from the dendrogram?

a. There were 28 data points in clustering analysis
b. The best no. of clusters for the analyzed data points is 4
c. The proximity function used is Average-link clustering
d. The above dendrogram interpretation is not possible for K-Means clustering analysis
59. ___________metric is examined to determine a reasonably optimal value of k.
1. Mean Square Error
2. Within Sum of Squares (WSS)
3. Speed
4. None of These
60. If an itemset is considered frequent, then any subset of the frequent itemset must also be frequent.
1. Apriori Property
2. Downward Closure Property
3. Either 1 or 2
4. Both 1 & 2
61. if {bread,eggs,milk} has a support of 0.15 and {bread,eggs} also has a support of 0.15, the confidence of rule {bread,eggs}→{milk} is
1. 0
2. 1
3. 2
4. 3
62. Confidence is a measure of how X and Y are really related rather than coincidentally happening together.
a. True
b. False
63. A high-confidence rule can sometimes be misleading because confidence does not consider support of the itemset in the rule consequent. Is This True?
a. Yes b. No
64. ____________ recommend items based on similarity measures between users and/or items.
1. Content Based Systems
2. Hybrid System
3. Collaborative Filtering Systems
4. None of These
65. There are __________ major Classification of Collaborative Filtering Mechanisms
1. 1
2. 2
3. 3
4. None of These
66. Movie Recommendation to peoples is an example of
1. User Based Recommendation
2. Item Based Recommendation
3. Knowledge Based Recommendation
4. Content Based Recommendation
67. ____________recommenders rely on an explicitly defined set of recommendation rules.
1. Constraint Based
2. Case Based
3. Content Based
4. User Based
68. Parallelized hybrid recommender systems operate dependently of one another and produce separate recommendation lists.
1. True
2. False
69. Association rules are sometimes referred to as
a. market basket analysis
b. Itemset Filtering
c. Frequent Itemset Analysis
d. None of these.
70. if 80% of all transactions contain itemset {bread}, then the support of {bread} is 0.8. Similarly, if 60% of all transactions contain itemset {bread,butter}, then the support of
{bread,butter} is
a. 0.4
b. 0.5
c. 0.6
d. 0.7
71. Lift is defined as the measure of certainty or trustworthiness associated with each discovered rule.
a. TRUE
b. FALSE
72. ___________ is able to identify trustworthy rules, but it cannot tell whether a rule is coincidental.
a. Lift
b. Confidence
c. Support
d. Leverage
73. ________________ recommend items based on similarity measures between users and/or items. The items recommended to a user are those preferred by similar users.
a. Collaborative Filtering System
b. Content Based Recommendation
c. Knowledge Based Recommendation
d. Hybrid Approaches
74. Pure collaborative approaches take a matrix of given user–item ratings as the only input and typically produce output. Is it Pure Collaborative?
a. Yes b. No
75. With respect to the determination of the set of similar users, one common measure used in
recommender systems is
a. Cosine Similarity Measure
b. Pearson’s correlation coefficient.
c. Mean Squared Error Method
d. None of these.
76. Large-scale e-commerce sites, often implement a different technique,
which is more apt for offline preprocessing and thus allows for the computation of recommendations in real time even for a very large rating matrix.
a. Item-Based Recommendation
b. User-Based Recommendation
c. Content-Based Recommendation
d. None of these
77. Here are two very short texts to compare and find the cosine similarity measure?
I. Julie loves me more than Linda loves me
II. Jane likes me more than Julie loves me a. 0.6
b. 0.7
c. 0.8
d. 0.9
78. ____________is based on the availability of item descriptions and a profile that assigns importance to these characteristics.
a. Item-Based Recommendation
b. User-Based Recommendation
c. Content-Based Recommendation.
d. None of these
79. Consider the features of a movie which are not relevant to a recommendation system.
a. The set of actors of the movie.
b. The Director
c. The Year in which the movie was made
d. The Budget of the movie.
80. A _____________ has been implemented, for similarity based retrieval under nearest neighbors.
a. k-nearest-neighbor method (kNN)
b. Conventional Neural Network (CNN)
c. Bayes Theorem
d. Naïve Bayes Classifier
81. Case-based recommenders focus on the retrieval of similar items on the basis of different types of similarity measures
a. TRUE
b. FALSE
82. In recommendation approaches, items are retrieved using similarity measures that describe to which extent item properties match some given user’s requirements.
a. Item-Based
b. Case-Based
c. Content-Based
d. User-Based
83. _________________are based on a sequenced order of techniques, in which each succeeding recommender only refines the recommendations of its predecessor.
a. Weighted Hybrids
b. Mixed Hybrids
c. Cascade Hybrids
d. Switching Hybrids
84. ________________require an oracle that decides which recommender should be used in a specific situation, depending on the user profile and/or the quality of recommendation
a. Weighted Hybrids
b. Mixed Hybrids
c. Cascade Hybrids
d. Switching Hybrids
85. Classification task referred to
1. A subdivision of a set of examples into a number of classes
2. A measure of the accuracy, of the classification of a concept that is given by a certain theory
3. The task of assigning a classification to a set of examples
4. None of these
86. The maximum value for entropy depends on the number of classes so if we have 8 Classes what will be the max entropy.
a. Max Entropy is 1
b. Max Entropy is 2
c. Max Entropy is 3
d. Max Entropy is 4
87. Data Analysis is a process of?
A. inspecting data
B. cleaning data
C. transforming data
D. All of the above
Explanation: Data Analysis is a process of inspecting, cleaning, transforming and modeling data with the goal of discovering useful information, suggesting conclusions and supporting decision-making.
88. Which of the following is not a major data analysis approaches?
A. Data Mining
B. Predictive Intelligence
C. Business Intelligence
D. Text Analytics
Explanation: Predictive Analytics is major data analysis approaches not Predictive Intelligence.
89. How many main statistical methodologies are used in data analysis?
A. 2
B. 3
C. 4
D. 5
Explanation: In data analysis, two main statistical methodologies are used Descriptive statistics and Inferential statistics.
90. In descriptive statistics, data from the entire population or a sample is summarized with ?
A. integer descriptors
B. floating descriptors
C. numerical descriptors
D. decimal descriptors
Explanation: In descriptive statistics, data from the entire population or a sample is summarized with numerical descriptors.
91. Data Analysis is defined by the statistician?
A. William S.
B. Hans Peter Luhn
C. Gregory Piatetsky-Shapiro
D. John Tukey
Explanation: Data Analysis is defined by the statistician John Tukey in 1961 as "Procedures for analyzing data.
92. Which of the following is true about hypothesis testing?
A. answering yes/no questions about the data
B. estimating numerical characteristics of the data
C. describing associations within the data
D. modeling relationships within the data
Explanation: answering yes/no questions about the data (hypothesis testing)
93. The goal of business intelligence is to allow easy interpretation of large volumes of data to identify new opportunities.
A. TRUE
B. FALSE
C. Can be true or false
D. Can not say
Explanation: The goal of business intelligence is to allow easy interpretation of large volumes of data to identify new opportunities.
94. The branch of statistics which deals with development of particular statistical methods is classified as
A. industry statistics
B. economic statistics
C. applied statistics
D. applied statistics
Explanation: The branch of statistics which deals with development of particular statistical methods is classified as applied statistics.
95. Which of the following is true about regression analysis?
A. answering yes/no questions about the data
B. estimating numerical characteristics of the data
C. modeling relationships within the data
D. describing associations within the data
Explanation: modeling relationships within the data (E.g. regression analysis).
96. Text Analytics, also referred to as Text Mining?
A. TRUE
B. FALSE
C. Can be true or false
D. Can not say
Explanation: Text Data Mining is the process of deriving high-quality information from text.
97. What is a hypothesis?
a. A statement that the researcher wants to test through the data
collected in a study.
b. A research question the results will answer.
c. A theory that underpins the study.
d. A statistical method for calculating the extent to which the results
could have happened by chance.
98. Qualitative data analysis is still a relatively new and rapidly
developing branch of research methodology.
a. True
b. False
99. The process of marking segments of data with symbols,
descriptive words, or category names is known as _______.
a. Concurring
b. Coding
c. Colouring
d. Segmenting
100. What is the cyclical process of collecting and analysing data
during a single research study called?
a. Interim analysis
b. Inter analysis
c. Inter-item analysis
d. Constant analysis
101. The process of quantifying data is referred to as _________.
a. Typology
b. Diagramming
c. Enumeration
d. Coding
102. An advantage of using computer programs for qualitative data is
that they _______.
a. Can reduce time required to analyse data (i.e., after the data are
transcribed)
b. Help in storing and organising data
c. Make many procedures available that are rarely done by hand
due to time constraints
d. All of the above
103. Boolean operators are words that are used to create logical
combinations.
a. True
b. False
104. __________ are the basic building blocks of qualitative data.
a. Categories
b. Units
c. Individuals
d. None of the above
105. This is the process of transforming qualitative research data from
written interviews or field notes into typed text.
a. Segmenting
b. Coding
c. Transcription
d. Mnemoning
106. A challenge of qualitative data analysis is that it often includes
data that are unwieldy and complex; it is a major challenge to make
sense of the large pool of data.
a. True
b. False
107. Hypothesis testing and estimation are both types of descriptive
statistics.
a. True
b. False
108. A set of data organised in a participants(rows)-byvariables(columns) format is known as a “data set.”
a. True
b. False
109. A graph that uses vertical bars to represent data is called a ___
a. Line graph
b. Bar graph
c. Scatterplot
d. Vertical graph
110. ___________ are used when you want to visually examine the
relationship between two quantitative variables.
a. Bar graphs
b. Pie graphs
c. Line graphs
d. Scatterplots
111. The denominator (bottom) of the z-score formula is
a. The standard deviation
b. The difference between a score and the mean
c. The range
d. The mean
112. Which of these distributions is used for a testing hypothesis?
a. Normal Distribution
b. Chi-Squared Distribution
c. Gamma Distribution
d. Poisson Distribution
113. A statement made about a population for testing purpose is
called?
a. Statistic
b. Hypothesis
c. Level of Significance
d. Test-Statistic
114. If the assumed hypothesis is tested for rejection considering it to
be true is called?
a. Null Hypothesis
b. Statistical Hypothesis
c. Simple Hypothesis
d. Composite Hypothesis
115. If the null hypothesis is false then which of the following is
accepted?
a. Null Hypothesis
b. Positive Hypothesis
c. Negative Hypothesis
d. Alternative Hypothesis.
116. Alternative Hypothesis is also called as?
a. Composite hypothesis
b. Research Hypothesis
c. Simple Hypothesis
d. Null Hypothesis
Hope u find these mcqs of DA(Data Analysis) of university SPPU helpful in your online MCQ exam.
(SPPU online DA mcq with answers)
2 Likes

by Akshay Sadawarte
SCTR's Pune Institute of Computer Technology Pune

Suggested Posts



